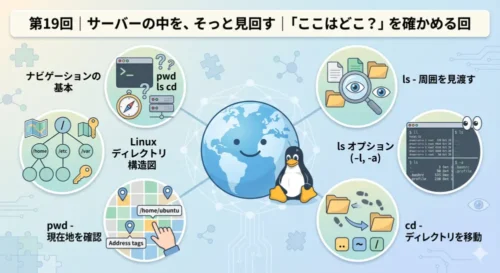
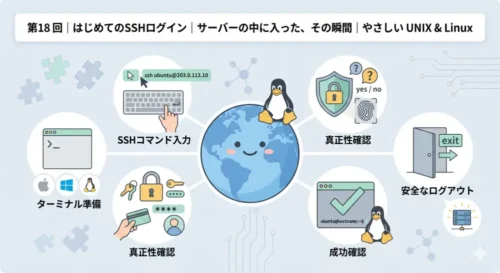
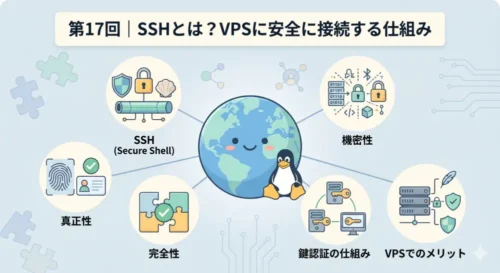
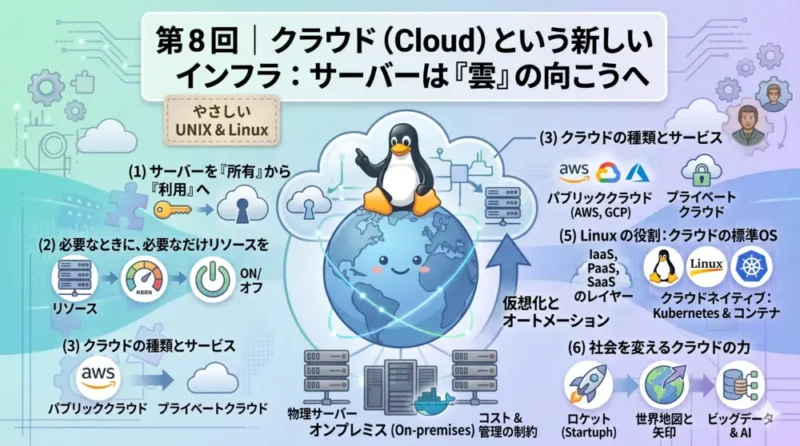
System Note
$ cat /proc/ai-disclosure
本記事の構成および論理分析にはAI(人工知能)を使用しています。情報の正確性は、システム管理者(UNIXユーザー)による手動検証済みです。

やさしい UNIX & Linux | 第7回
第6回では、インターネットの誕生から Linux が Web サーバーの標準 OS として定着するまでの流れを確認しました。TCP/IP という共通規格、WWW の登場、そして Linux と Apache の組み合わせが、Web インフラの基盤を作ったという話です。
しかし、サーバーとネットワークが整っただけでは、世界は変わりません。次の変化は「ウェブの使われ方」そのものに起きました。ブラウザの登場でウェブが視覚的になり、ページが爆発的に増え、そして膨大な情報を探すための仕組みとして検索エンジンが生まれます。
この記事では、1990年代から2000年代にかけてのウェブの変化と、検索エンジンが社会に与えた影響を整理します。
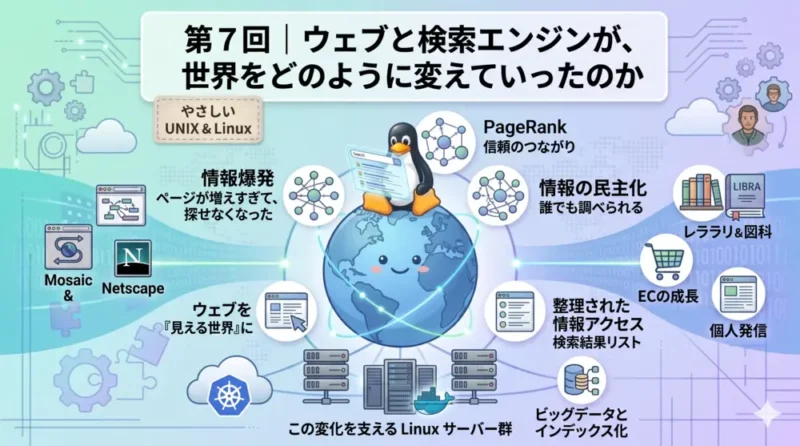
WWW が公開された 1991年当初、ウェブを閲覧するには専用のコマンドを使う必要があり、一般の人が使いこなせるものではありませんでした。転機となったのは 1993年に公開された Mosaic です。
Mosaic は、イリノイ大学の研究チームが開発した初のグラフィカル Web ブラウザです。テキストと画像を同じ画面に表示でき、リンクをクリックするだけで別のページに移動できる設計が、ウェブを「誰でも使えるもの」にしました。
1994年には Mosaic の主要開発者たちが立ち上げた Netscape Communications が Netscape Navigator を公開し、瞬く間に世界中に普及しました。ウェブは研究者だけのものから、一般の人々が毎日使うメディアへと変わっていきます。
ブラウザの普及とともに、ウェブページの数は急激に増えました。1993年には世界で数百程度だったウェブサイトが、1996年には 100万サイトを超え、2000年代初頭には数千万規模になっていきます。
ページが増えると、「目的の情報がどこにあるかわからない」という問題が生じます。リンクをたどって探す方法では、膨大なページの中から必要な情報に到達できません。
最初の解決策は「ディレクトリ型」の整理でした。1994年に誕生した Yahoo! は、人間が手作業でウェブサイトを分類し、カテゴリ別に一覧表示するサービスです。ただし、増加するページの速度に人間の分類作業が追いつかなくなるのは時間の問題でした。
人手による整理の限界を補ったのが、自動でウェブを巡回する仕組みです。「クローラー」と呼ばれるプログラムがウェブ上のリンクをたどりながらページを収集し、その内容をデータベース(インデックス)に蓄積します。ユーザーが言葉を入力すると、インデックスを検索して関連するページを表示します。
1995年に公開された AltaVista は、当時最大規模のインデックスを持つ検索エンジンとして注目を集めました。「ウェブで何でも調べられる」という感覚を、多くの人が初めて体験した瞬間です。
ただし、この時代の検索は「入力した言葉がページ内に多く含まれているか」を主な判断基準にしていたため、質の高い情報が上位に来るとは限らず、精度に課題がありました。
検索の精度を大きく変えたのが、1998年に登場した Google です。スタンフォード大学の大学院生だったラリー・ペイジとサーゲイ・ブリンが開発した PageRank というアルゴリズムが、従来の検索との決定的な違いをもたらしました。
PageRank の発想はシンプルです。「多くのページからリンクされているページは、多くの人が参照する価値のある情報を持っている可能性が高い」という考え方です。リンクを単なるナビゲーションの道ではなく、他のページへの「推薦」として解釈しました。
さらに、推薦元のページ自体が多くからリンクされているほど、その推薦の重みも大きくなります。「信頼のつながり」を計算することで、関連性が高く、かつ質の高いページを優先的に表示できるようになりました。Google はこの仕組みで一気に検索の標準になっていきます。
ウェブと検索エンジンがそろったことで、社会の変化は急速に進みました。
情報へのアクセスが民主化された 専門家や研究機関だけが持っていた情報が、誰でも検索一つで調べられるようになりました。学習・調査・ニュースの取得が、特別な場所や手続きを必要としない日常的な行為になります。
場所と距離の意味が変わった 店舗・企業の情報、商品の比較、仕事の探し方まで、物理的に移動しなくても手に入るようになりました。電子商取引(EC)の成長も、このアクセスのしやすさが土台にあります。
個人が発信できるようになった ページを公開すれば、誰でも世界に向けて情報を届けられます。大手メディアだけでなく、個人のブログや専門サイトが影響力を持つようになりました。
ウェブと検索エンジンの急成長の裏側では、膨大な数のサーバーが動き続けていました。Yahoo!・Google・Amazon といった初期のインターネット企業が選んだのも Linux でした。
理由は第6回で確認したのと同じです。無償で使えるコスト優位性、長期間の安定稼働、GNU ツール群による柔軟な運用環境。数千台・数万台規模のサーバーを並べて動かす「Web スケール」の運用において、Linux のオープンソースという性質は特に大きな強みになりました。
UNIX の思想である「小さな部品を組み合わせる」「開かれた標準を使う」というアプローチは、ウェブの設計(HTML・HTTP・URL の公開標準化)とも深く共鳴していました。インターネット企業の成長と Linux の普及は、この時期に強く結びついていきます。
第7回で整理した流れをまとめます。
ウェブが「技術者だけのもの」から「社会のインフラ」になるまでの変化は、検索エンジンという発明があってはじめて完成しました。そして、その裏側では Linux が静かに世界を支え続けていました。
第7回では、ブラウザと検索エンジンの登場がウェブをどのように変えたか、そして Linux がその成長を支えた経緯を整理しました。
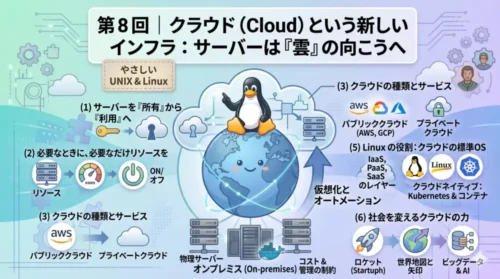
第8回では、こうした Web サービスや検索エンジンを動かし続けている「サーバー」という存在に目を向けます。サーバーとはそもそも何か、どのような種類があり、どのように役割を分担しているのか。目には見えないけれど、インターネットを支えている土台の仕組みを整理していきます。