System Note
$ cat /proc/ai-disclosure
本記事の構成および論理分析にはAI(人工知能)を使用しています。情報の正確性は、システム管理者(UNIXユーザー)による手動検証済みです。

やさしい UNIX & Linux | 第15回
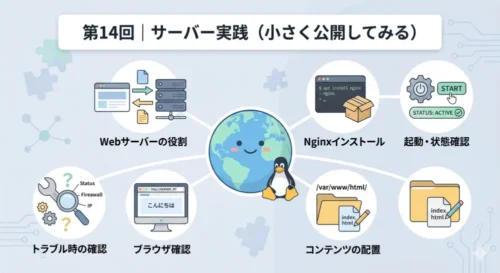
第 14 回では、Nginx をインストールして自分のページをブラウザで表示するところまでを確認しました。サーバーが外からのアクセスに応答する体験です。
サーバーを動かし続けると、いつかは「ページが表示されない」「SSH で入れない」といった状況に直面します。これはサーバーを使う誰もが通る道です。この回では、トラブルが起きたときの考え方と、状況を把握するための具体的な手順を整理します。
ページが表示されなくなると、最初は「何かを壊してしまった」と感じるかもしれません。しかし多くの場合、サーバーが完全に壊れているわけではありません。設定ミス・サービスの停止・ネットワークの問題など、原因は必ずどこかにあり、特定できれば対処できます。
焦って次々と設定を変えると、状況がわからなくなります。まず「今何が起きているか」を把握することが、解決への最短経路です。
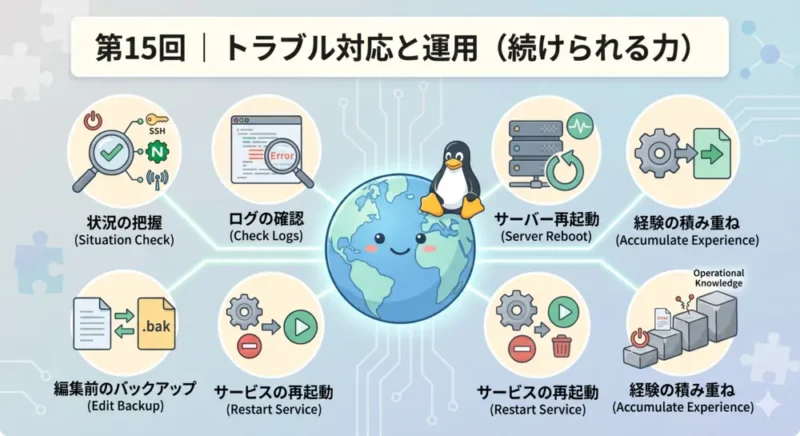
トラブルが起きたとき、次の順番で状況を確認します。
Nginx の状態確認は、第 14 回でも使った次のコマンドです。
sudo systemctl status nginxinactive と表示されていれば停止しています。再起動するには次のコマンドを使います。
sudo systemctl restart nginxサービスが起動に失敗したり、エラーが発生したりすると、その記録がログに残ります。ログはサーバーの「診断記録」です。英語でも、すべてを理解できなくても構いません。エラーが起きた時刻付近に何が書かれているかを確認するだけで、手がかりになります。
Nginx のエラーログを確認するコマンドは次のとおりです。
sudo cat /var/log/nginx/error.logsystemd 経由で起動・停止の記録を確認するには次のコマンドが便利です。
sudo journalctl -xeログに Permission denied や No such file or directory といった文字が見えれば、権限の問題やファイルの不在が原因である可能性が高いです。エラーメッセージをそのままコピーして検索すると、解決方法が見つかることがほとんどです。
設定ファイルを変更してサービスが止まった場合、元の設定に戻すことが最も確実な対処です。設定ファイルを編集する前に、コピーを取っておく習慣をつけると安心です。
sudo cp /etc/nginx/nginx.conf /etc/nginx/nginx.conf.bak.bak という拡張子を付けてバックアップを作成しておけば、変更後に問題が起きても元のファイルに戻せます。
sudo cp /etc/nginx/nginx.conf.bak /etc/nginx/nginx.conf「戻れる場所がある」という状態で作業すると、心理的な余裕が生まれ、落ち着いて問題を調べられます。無理に原因を探し続けるより、いったん動いていた状態に戻してから改めて変更を加える方が、結果的に早く解決することが多いです。
原因がわからないまま何かおかしい、という状況では、サービスの再起動が有効な場合があります。一時的なメモリ不足・プロセスのハングアップ・ネットワーク接続の切断などは、再起動で解消されることがあります。
特定のサービスを再起動するのが安全です。サーバー全体を再起動する場合は SSH 接続が切れることを念頭に置きます。
# Nginx だけ再起動
sudo systemctl restart nginx
# サーバー全体を再起動
sudo rebootreboot を実行するとすぐに接続が切れます。数十秒〜1 分ほど待ってから再度 SSH で接続します。
サーバーをゼロ・トラブルで動かし続けることは現実的ではありません。企業の本番サーバーでも、障害は起きます。大切なのは、トラブルが起きたときに「状況を把握し・原因を特定し・対処できる」という経験を積み重ねることです。
一度経験したトラブルは、次に同じ状況が起きたとき対処できます。ログの見方・サービスの起動確認・バックアップと復元、これらを一通り体験しておくことが、運用の土台になります。
完璧な設定を最初から目指すより、「小さく動かし・少し壊し・直す」を繰り返す中で理解が深まっていきます。続けることが、もっとも確実な上達方法です。
第 15 回で確認したポイントをまとめます。
/var/log/nginx/error.log や journalctl -xe でヒントを探す.bak コピーを作る。「戻せる状態」を維持するsystemctl restart でサービス単体を、reboot でサーバー全体を再起動できるトラブルに向き合う経験は、サーバーの仕組みを理解する最短経路のひとつです。
第 15 回では、トラブルが起きたときの確認手順と、運用を続けるための考え方を整理しました。
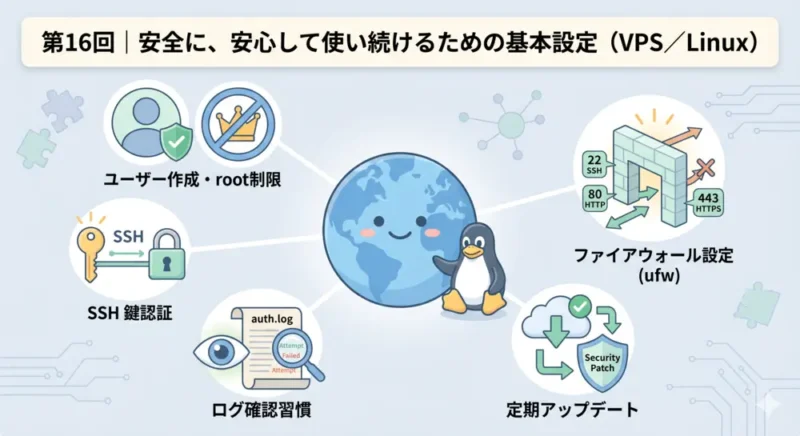
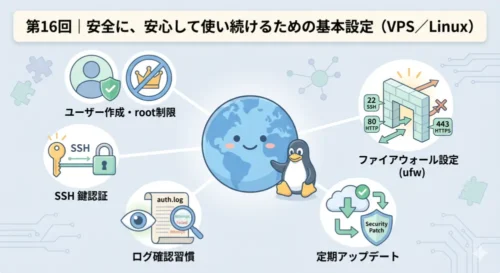
第 16 回では、トラブルを「減らす」ための話に進みます。VPS を安全に使い続けるための基本設定として、ファイアウォールの設定・SSH の鍵認証・不要なサービスの停止といった、最初に整えておくべき項目を確認していきます。